LASfile <- system.file("extdata", "Topography.laz", package="lidR")
las <- readLAS(LASfile, select = "xyzrn")las <- classify_ground(las, algorithm = pmf(ws = 5, th = 3))Classification of ground points is an important step in processing point cloud data. Distinguishing between ground and non-ground points allows creation of a continuous model of terrain elevation (see Chapter 5)). Many algorithms have been reported in the literature and lidR currently provides four of them: Progressive Morphological Filter (PMF), Cloth Simulation Function (CSF), Multiscale Curvature Classification (MCC) and Progressive TIN densification (PTD) usable with the function classify_ground().
In January 2026, we added Progressive TIN Densification (PTD) to lidR 4.3.0. We strongly recommend using this algorithm exclusively, as it outperforms all others. For legacy reasons, the algorithms described in Sections Section 4.1, Section 4.2, and Section 4.3 are still included in the book and are maintained as is, but new readers can move on Section 4.4.
The implementation of PMF algorithm in lidR is based on the method described in Zhang et al. (2003) with some technical modifications. The original method is raster-based, while lidR performs point-based morphological operations because lidR is a point cloud oriented software. The main step of the methods are summarised in the figure below:
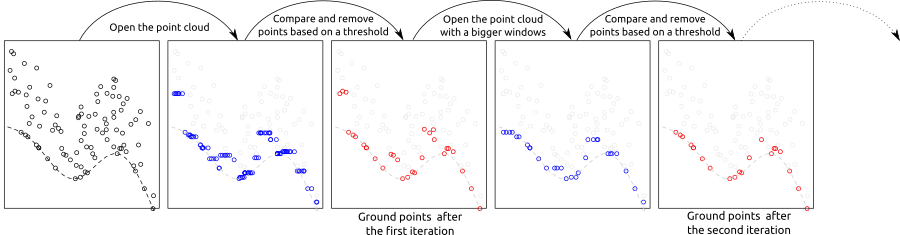
The pmf() function requires defining the following input parameters: ws (window size or sequence of window sizes), and th (threshold size or sequence of threshold heights). More experienced users may experiment with these parameters to achieve best classification accuracy, however lidR contains util_makeZhangParam() function that includes the default parameter values described in Zhang et al. (2003).
LASfile <- system.file("extdata", "Topography.laz", package="lidR")
las <- readLAS(LASfile, select = "xyzrn")las <- classify_ground(las, algorithm = pmf(ws = 5, th = 3))We can now visualize the result:
plot(las, color = "Classification", size = 3, bg = "white") 
To better illustrate the classification results we can generate and plot a cross section of the point cloud (see Section 3.3)).
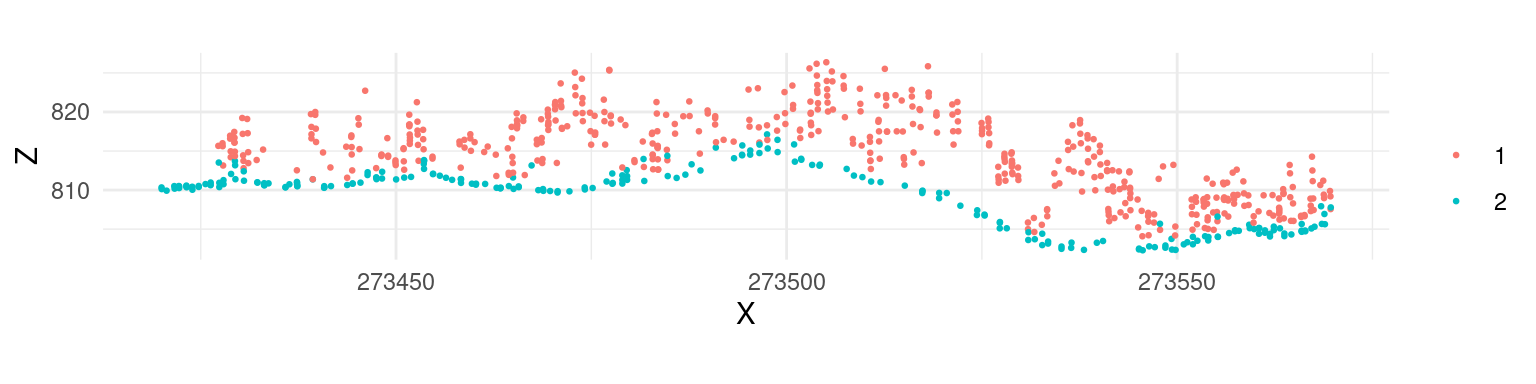
We can see that although the classification worked, there are multiple points above terrain that are classified 2 (i.e. “ground” according to ASPRS specifications). This clearly indicates that additional filtering steps are needed and that both ws and th parameters should be adjusted. Below we use multiple values for the two parameters instead of a single value in the example above.
ws <- seq(3, 12, 3)
th <- seq(0.1, 1.5, length.out = length(ws))
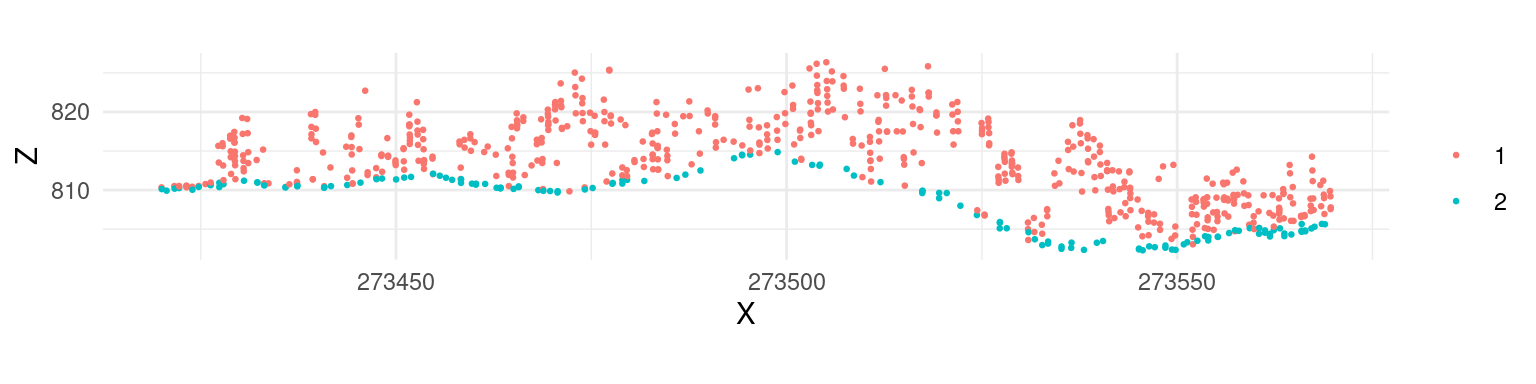
las <- classify_ground(las, algorithm = pmf(ws = ws, th = th))After this adjustment the classification result changed, and points in the canopy are no longer classified as “ground”.
Cloth simulation filtering (CSF) uses the Zhang et al 2016 algorithm and consists of simulating a piece of cloth draped over a reversed point cloud. In this method the point cloud is turned upside down and then a cloth is dropped on the inverted surface. Ground points are determined by analyzing the interactions between the nodes of the cloth and the inverted surface. The cloth simulation itself is based on a grid that consists of particles with mass and interconnections that together determine the three-dimensional position and shape of the cloth.

The csf() functions use the default values proposed by Zhang et al 2016 and can be used without providing any arguments.
las <- classify_ground(las, algorithm = csf())Similar to the previous examples, classification results can be assessed using a cross section:
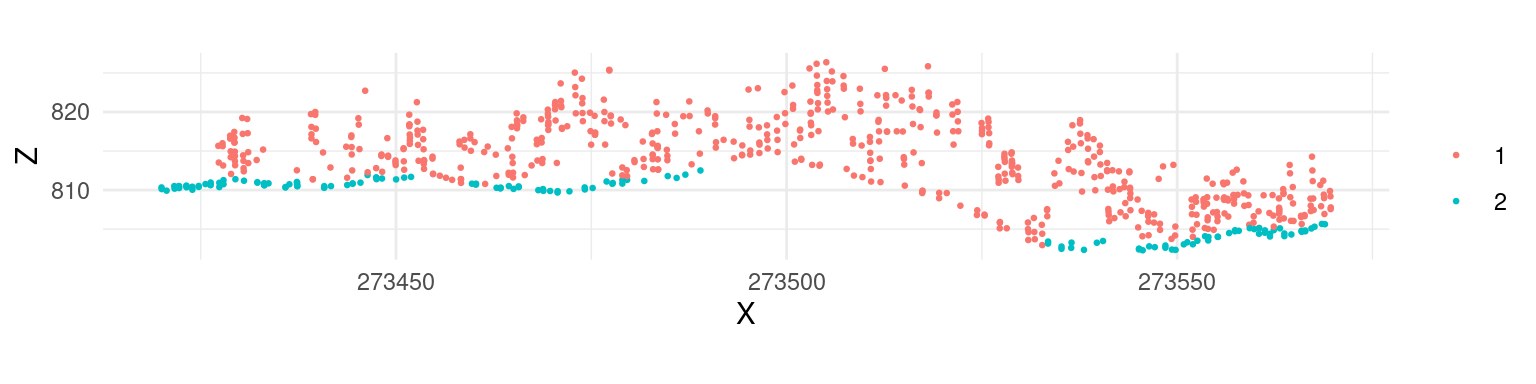
While the default parameters of csf() are designed to be universal and provide accurate classification results, according to the original paper, it’s apparent that the algorithm did not work properly in our example because a significant portion of points located in the ground were not classified. In such cases the algorithm parameters need to be tuned to improve the result. For this particular data set a set of parameters that resulted in an improved classification result were formulated as follows:
mycsf <- csf(sloop_smooth = TRUE, class_threshold = 1, cloth_resolution = 1, time_step = 1)
las <- classify_ground(las, mycsf)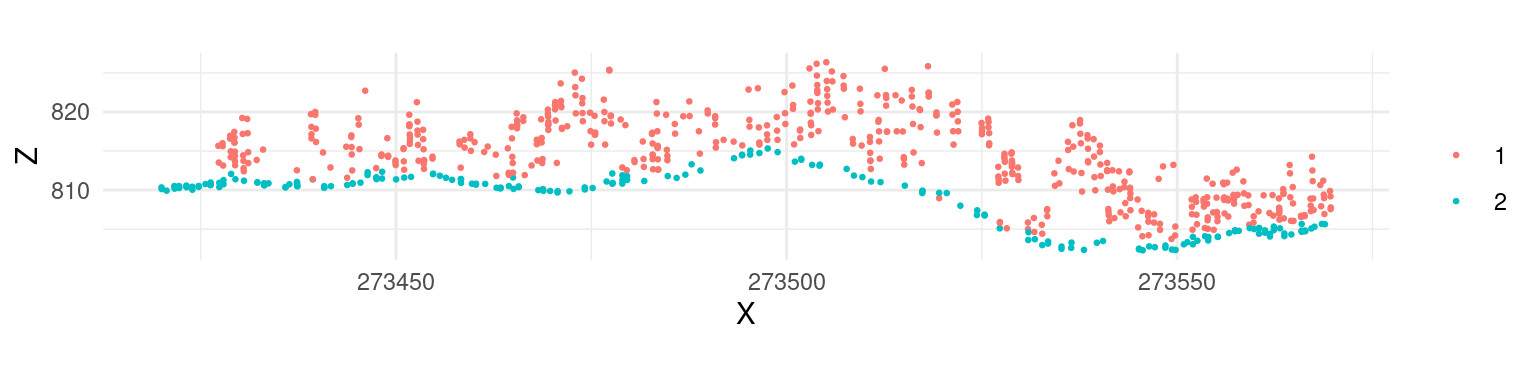
We can also subset only the ground points to display the results in 3D
gnd <- filter_ground(las)
plot(gnd, size = 3, bg = "white") 
Multiscale Curvature Classification (MCC) uses the Evans and Hudak 2016 algorithm originally implemented in the mcc-lidar software.
las <- classify_ground(las, mcc(1.5,0.3))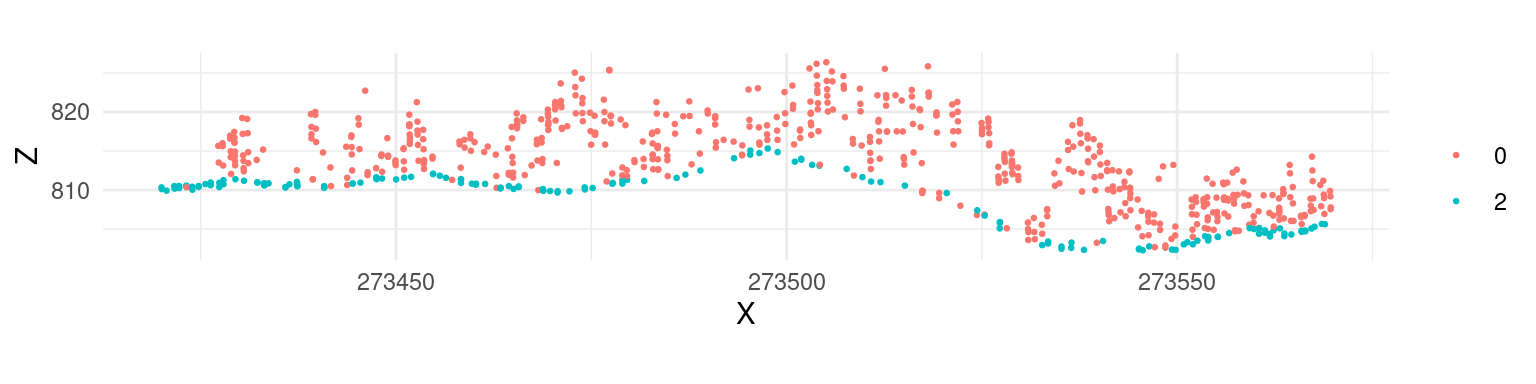
Progressive TIN Densification (PTD) was proposed by Axelsson (2000). It the most widely used algorithms in industry and in closed-source software such as LAStools or TerraScan (with potentially undocumented variations). It generally outperforms PMF, CSF, and MCC, especially in complex terrain such as mountains.
In early 2026, we added PTD to lidR and we now recommend using it exclusively.
PTD starts with a small set of points that are very likely to be on the ground (called seeds), usually the lowest points in the area, and uses them to create an initial Triangulated Irregular Network (TIN). Then, other points are tested one by one and added to the TIN if they fit the shape of the current surface, based on simple rules such as maximum slope or height difference with the current TIN. Points that are too high or that create sharp angles are rejected as non-ground objects (trees, buildings, etc.). By progressively adding only compatible points, the TIN gradually adapts to the true terrain, producing a reliable ground model even in complex landscapes.
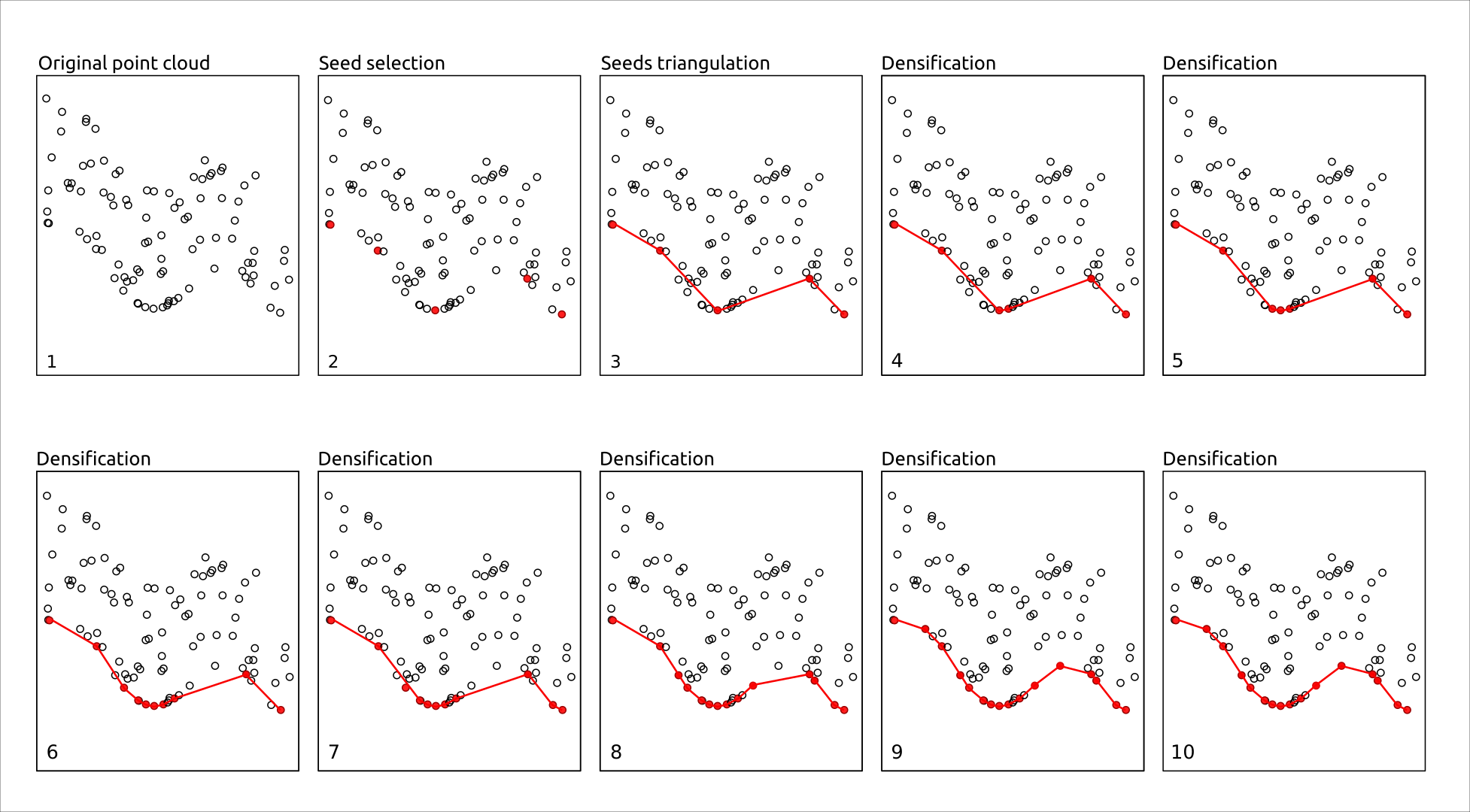
Unlike PMF, CSF, or RMCC, which classify all ground points based on a buffer above a reference surface (e.g. +10 cm) and therefore classify ground points without spacing limits, PTD can stop the densification when triangles become too small. This effectively introduces a maximum spacing between ground points, avoiding useless (and even harmful for computational purposes) over-densification of ground points.
las <- classify_ground(las, ptd(20))PTD starts by selecting seeds. A seed is the lowest point found within each cell of a grid with resolution res. This parameter is very important because all seeds must be actual ground points. If some seeds are not ground points, the final classification will be incorrect (some low noise points are tolerated; see later). The resolution must be chosen large enough so that the lowest point in each cell is actually a ground point and not, for example, a rooftop or a tree (see figure below). At the same time, we want to have as many seeds as possible to capture steep variations in the terrain. If the seeds are too widely spaced, PTD may miss and truncate some mountain tops (see figure below).
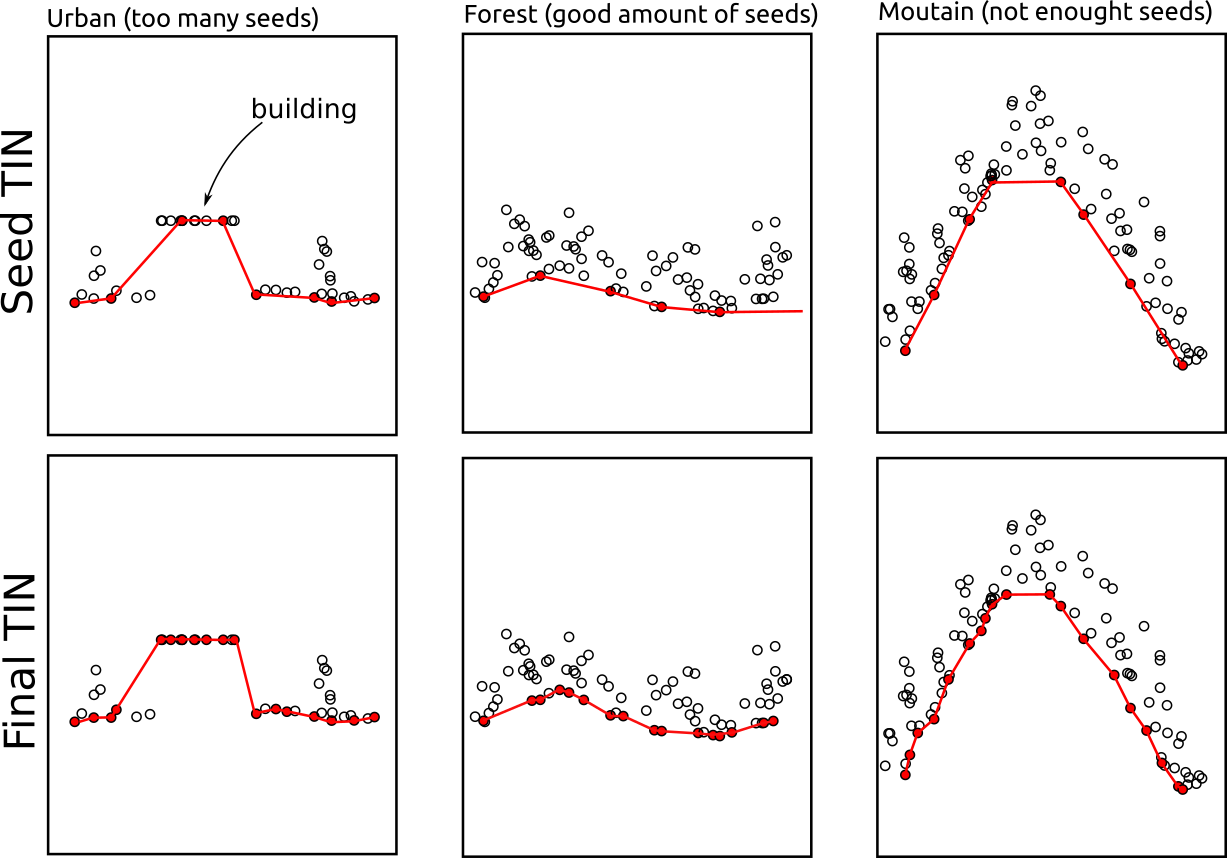
In urban environments, we recommend using res = 50 or larger to ensure that rooftops are not captured as seeds. In forested environments with standard condition, we recommend res = 20. In steep mountainous terrain, we recommend res = 10. In some cases, depending on the acquisition settings and forest cover, the point cloud may contain very few ground points. In this case, res must be increased to avoid capturing non-ground points.
The densification is governed by two criteria. For each triangle, a new point is inserted into the triangulation if the angle is below a threshold (parameter angle) and if its distance is below a threshold (parameter distance). The default settings work well in most standard contexts. For the definition of angle and distance the reader can refer to the PTD publication linked above.
Changing distance and angle is, however, mandatory in very steep mountainous areas, where PTD must tolerate strong local variations and therefore be less conservative. In mountainous terrain, we recommend using angle = 40 and distance = 3.
In very flat terrain, in order to reduce the risk of misclassification, users can make PTD more conservative with, for example, angle = 10 and distance = 1.
In the original PTD, low outliers are, by construction, a serious issue. Low outliers are almost systematically the lowest points of each grid cell but are not ground points. Consequently, at the end of the densification, even in the best case, the ground classification contains outliers that will generate spikes in the DTM.
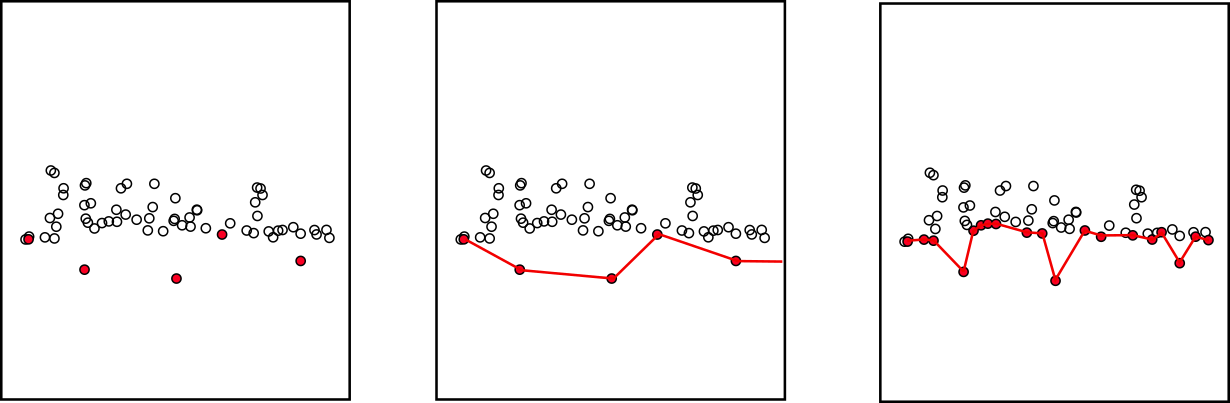
The best way to avoid this problem is, of course, to feed PTD with a clean point cloud from which outliers have already been removed upstream. However, lidR’s PTD is equipped with and enhanced by an internal outlier removal system that detects and cleans ground outliers. This procedure is robust and has produced very satisfactory results on all datasets tested.
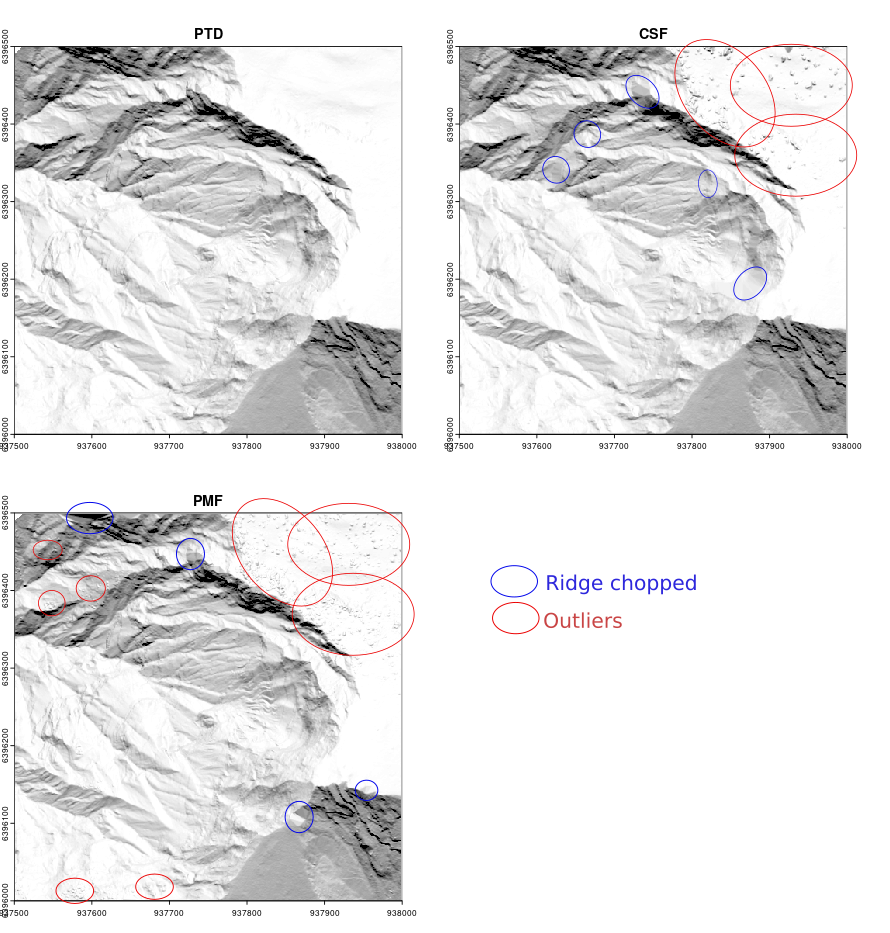
See Chapter 5 to learn how to build a DTM. Below are the results of the best ground classifications and DTMs we were able to achieve with CSF, PMF, and PTD in a complex mountainous scene with sharp ridges and steep slopes. Although the images are rendered small in this book, we can observe that ridges and slopes are better classified with PTD and that PTD does not produce the numerous bumps caused by outlier misclassification in vegetated areas, which often result from overly permissive parameter settings required to handle such complex scenes.
Overall, PTD outperforms the other methods in all contexts and is much easier to configure, as the effects of its parameters are easy to understand and anticipate.
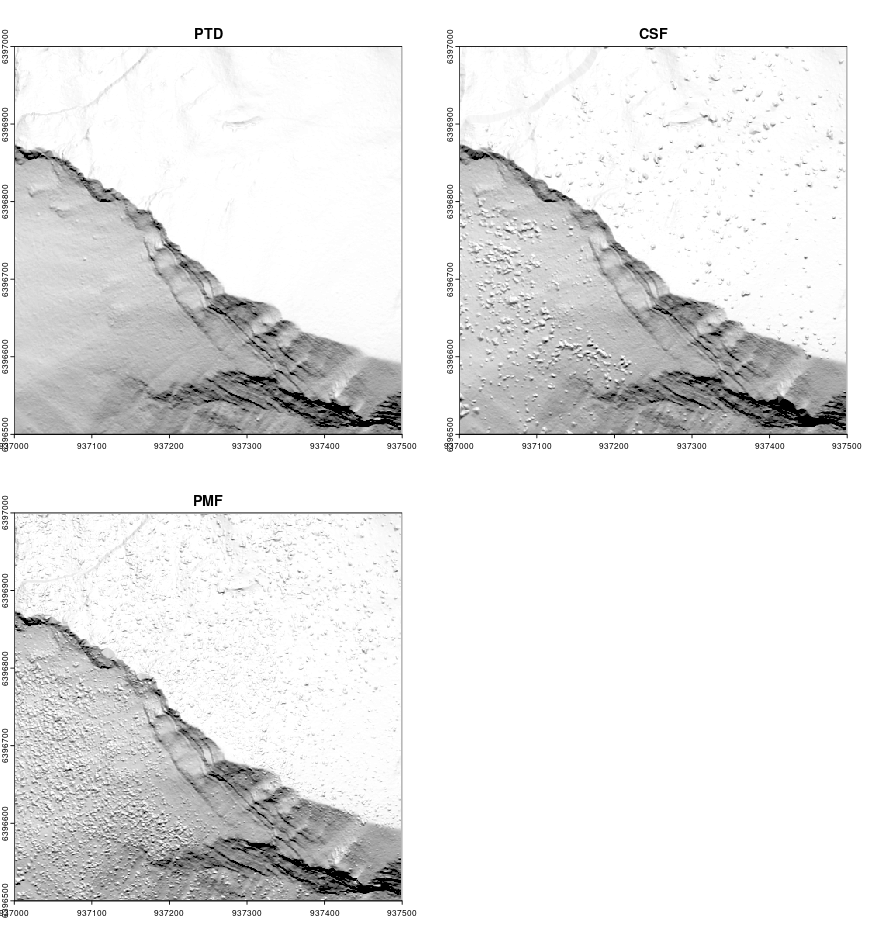
No matter which algorithm is used in lidR or other software, ground classification will be weaker at the edges of point clouds as the algorithm must analyze the local neighbourhood (which is missing on edges). To find ground points, an algorithm need to analyze the local neighborhood or local context that is missing at edge areas. When processing point clouds it’s important to always consider a buffer around the region of interest to avoid edge artifacts. lidR has tools to manage buffered tiles and this advanced use of the package will be covered in Chapter 15).
Ground segmentation is not limited to the 3 methods described above. Many more have been presented and described in the literature. In Chapter 20 we will learn how to create a plugin algorithm and test it seamlessly in R with lidR using a syntax like:
las <- classify_ground(las, algorithm = my_new_method(param1 = 0.05))